雑記帳
古いままのページをなんとかしたいと思って、CSSを収集、解析するスクリプトを組もうとしています。「スクレイピング」ということになるのかな。スクレイピングではPythonを使うのが一般的なようですが、それよりも気楽に書けるような気がするのでPHPを使うことにしました(「気楽」に書けるからといって「容易」に完成するとは限らないのだけど)。
PHPでのスクレイピングではphpQueryがよく使われているようなので、これ(phpQuery-onefile)を使います。
こんな感じ。
<?php
require_once("./phpQuery-onefile.php");
$url = "http://example.jp/foo/bar/hoge.html";
$html = file_get_contents($url);
$doc = phpQuery::newDocument($html);
foreach($doc["link[rel$='stylesheet']"] as $tt )
{
echo pq($tt)->attr("href")."\n";
}
foreach($doc["style"] as $tt )
{
echo pq($tt)->text();
}
foreach($doc["*[style]"] as $tt )
{
echo pq($tt)->attr("style")."\n";
}
?>
このコードでは画面に表示するだけですが、取得できたCSSから必要な部分を抜き出したり、指定された外部CSSファイルを読みに行ったりする処理を加えていくわけです。
さて困ったことがあります。文字化けしたりしなかったりするのです。
phpQueryの中身を見てみると、<meta http-equiv="Content-Type" content="text/html;charset=(文字コード)"> の形での文字コード指定をチェックしている部分がありますが、取りこぼしがあるようです。さらに、この文字コードの指定方法は古いもので、HTML5の書式 <meta charset="(文字コード)"> には対応してないようです。
読み込んだHTMLをphpQueryに渡すのではなく、phpQueryに直接WEB上のHTMLファイルを読みに行かせるとレスポンスヘッダの文字コード指定を見てくれるようですが(たぶん)、皆さんご存知の通りレスポンスヘッダに文字コード指定のない場合が多いので解決にはなりません。
ということで、読み込んだHTMLをphpQueryに渡す前に文字コード変換してやることにしました。そしてphpQueryの方でさらに文字コード変換するとまずいので、META要素を削除しています。
$html = mb_convert_encoding($html, "UTF-8", "SJIS,JIS,EUC-JP,UTF-8");
$html = preg_replace ("/<meta.*?>/i", "", $html );
$doc = phpQuery::newDocument($html);
UTF-8へ変換しているのはもちろんこのPHPスクリプトをUTF-8で記述しているからです。
絵をJPEGファイル化するときにメタデータを埋め込もうぜ!という話です。
画像ファイルには作者名や画像の説明などのメタデータを埋め込むことができます。昔はペイントツール系ではPhotoshopくらいしかメタデータを扱えるものがなかったのですが、最近は他にも扱えるツールが出てきていますので見ていきましょう。
今回チェックしたツールは Photoshop、GIMP、Krita、PaintShop Pro の4つ。このような情報を埋め込むとしましょう。
住所や電話番号を公開している人は少数派かもしれませんが例として入れています。
Photoshop CC 2019
→Adobe Photoshopの購入 | 最高の写真、画像、デザイン編集ソフト
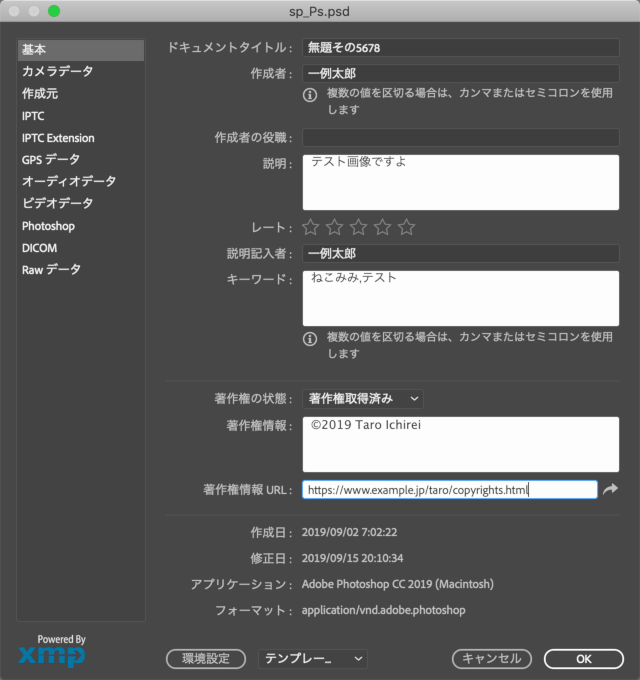
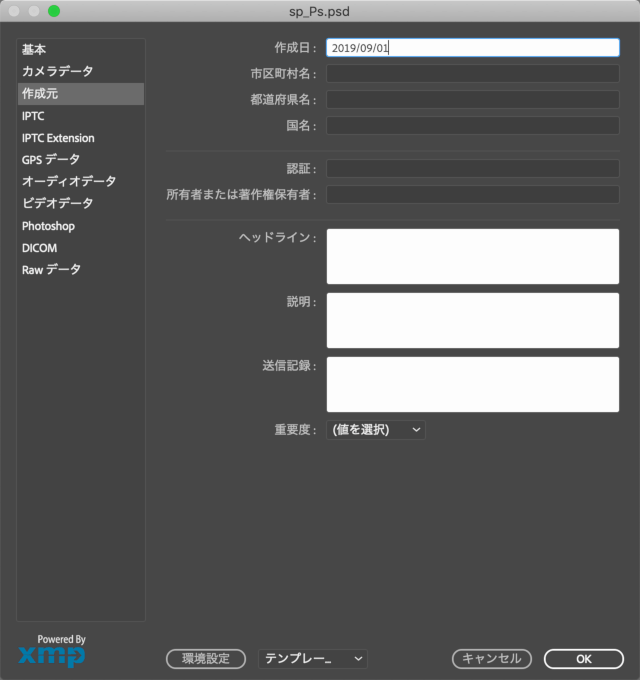
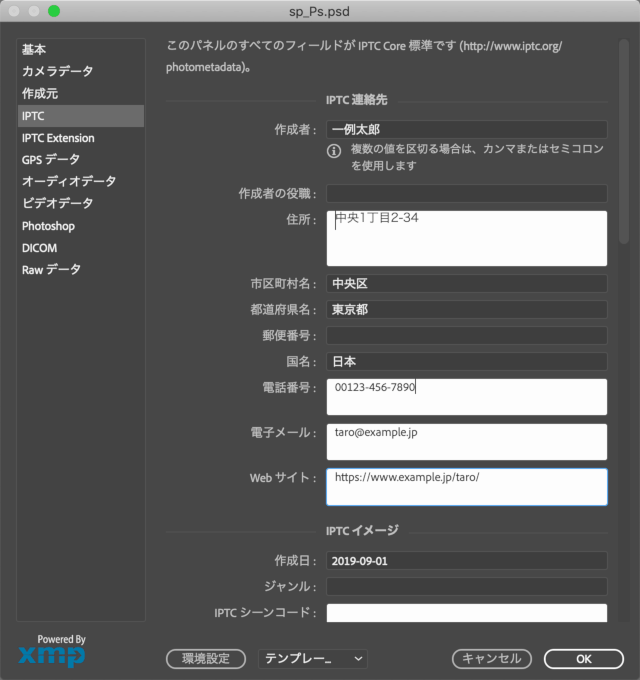 メニューの ファイル > ファイル情報... でダイアログが開きます。メタデータの種別ごとにタブが分かれています。
メニューの ファイル > ファイル情報... でダイアログが開きます。メタデータの種別ごとにタブが分かれています。
PhotoshopではJPEGで保存するには「別名で保存...」か「書き出し...」を使います。(他に「Web用に保存(従来)」もありますがここでは割愛)
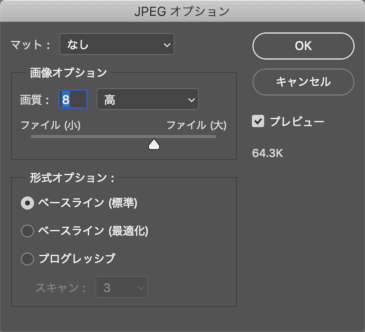 「別名で保存...」はメタデータも一緒に保存されます(メタデータを保存しない選択はありません)。
「別名で保存...」はメタデータも一緒に保存されます(メタデータを保存しない選択はありません)。
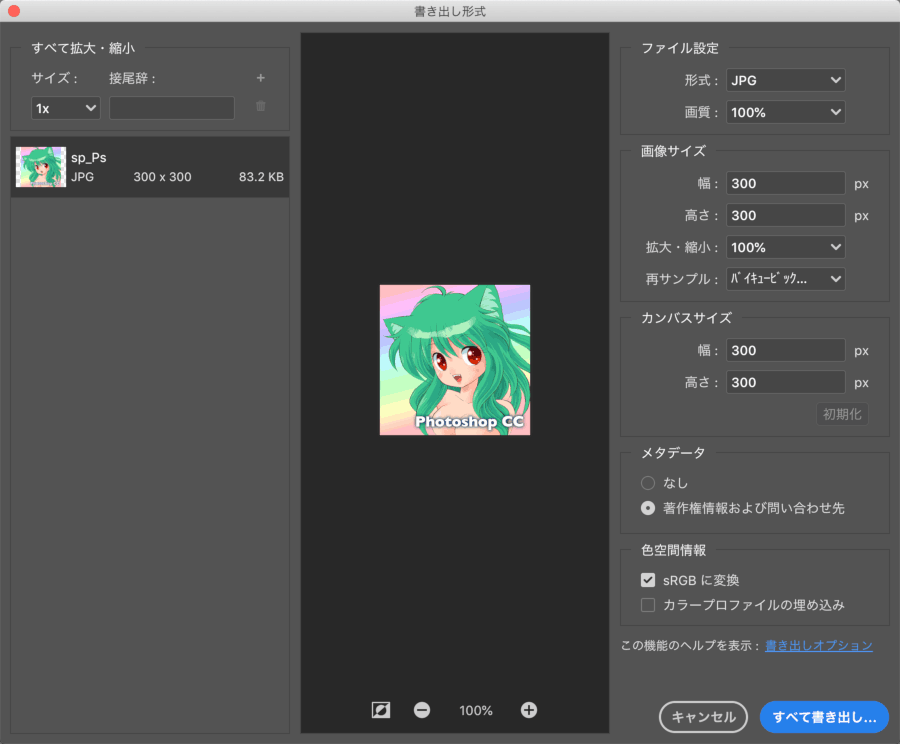 「書き出し...」でメタデータも一緒に保存するには、メタデータ欄の「著作権情報および問い合わせ先」を選びます。
「書き出し...」でメタデータも一緒に保存するには、メタデータ欄の「著作権情報および問い合わせ先」を選びます。
GIMP 2.10
→GIMP - GNU Image Manipulation Program
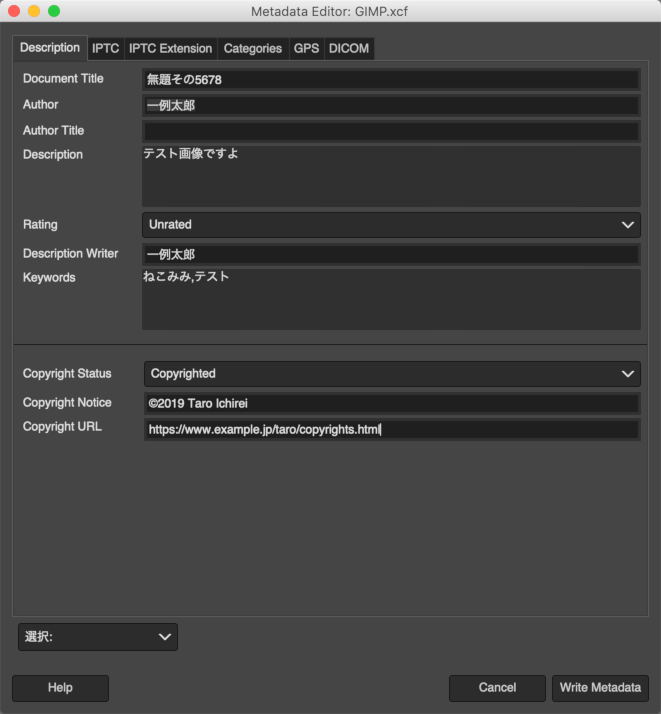
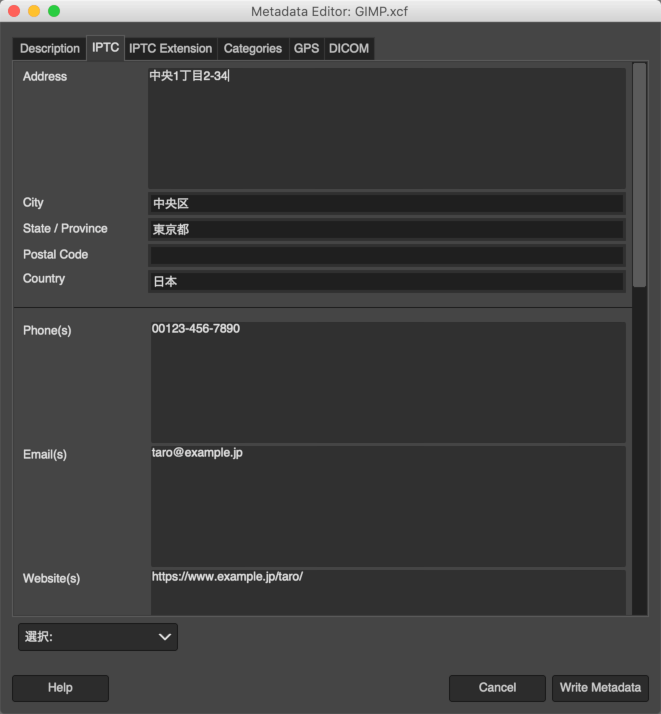 メニューの 画像 > メタデータ > Edit Metadata でダイアログが開きます。メタデータの種別ごとにタブが分かれています。
スクリーンショットには写っていませんが、IPTCタブのWebsite(s)欄の下には作成日の欄があります。
メニューの 画像 > メタデータ > Edit Metadata でダイアログが開きます。メタデータの種別ごとにタブが分かれています。
スクリーンショットには写っていませんが、IPTCタブのWebsite(s)欄の下には作成日の欄があります。
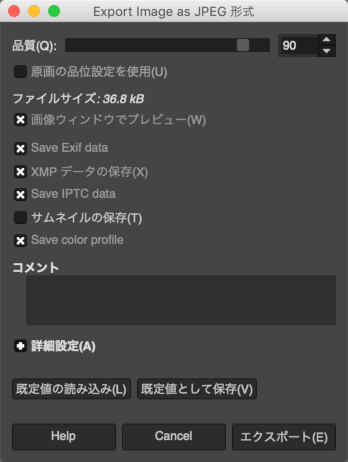 JPEGファイルにメタデータも一緒に保存するには、「Save Exif data」「XMPデータの保存」「Save IPTC data」の項目にチェックを入れておきます。
JPEGファイルにメタデータも一緒に保存するには、「Save Exif data」「XMPデータの保存」「Save IPTC data」の項目にチェックを入れておきます。
Krita 4.2
→Krita | デジタルでのお絵描きと創造の自由を
メタデータは、「作者」と「画像」の2つに設定個所が分かれています。
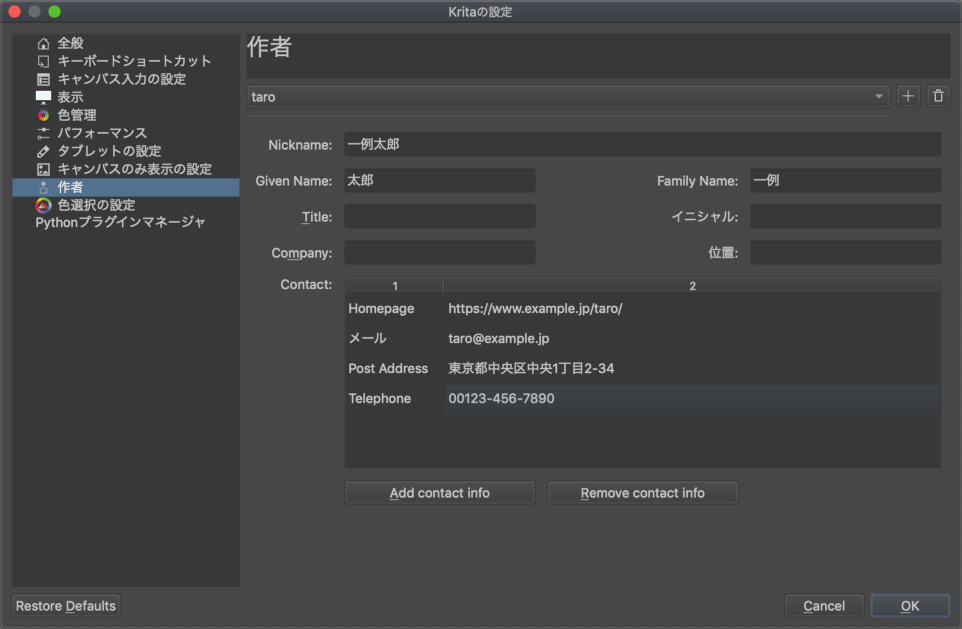 「作者」の情報は、Preferenses(Kreitaの設定)の中にあります。
最初は「Anonymous」の設定しかないので、「+」ボタンを押して新しい作者の情報を作ります。
Contact(連絡先)の項目は「Add Contact info」ボタンを押すと追加できます。最初は「Homepage」になってますが、プルダウンメニューになっていて、クリックして選ぶことができます。
「作者」の情報は、Preferenses(Kreitaの設定)の中にあります。
最初は「Anonymous」の設定しかないので、「+」ボタンを押して新しい作者の情報を作ります。
Contact(連絡先)の項目は「Add Contact info」ボタンを押すと追加できます。最初は「Homepage」になってますが、プルダウンメニューになっていて、クリックして選ぶことができます。
作者情報の設定ができたら、メニューの 設定 > アクティブな作者プロフィール でその設定を選びます。
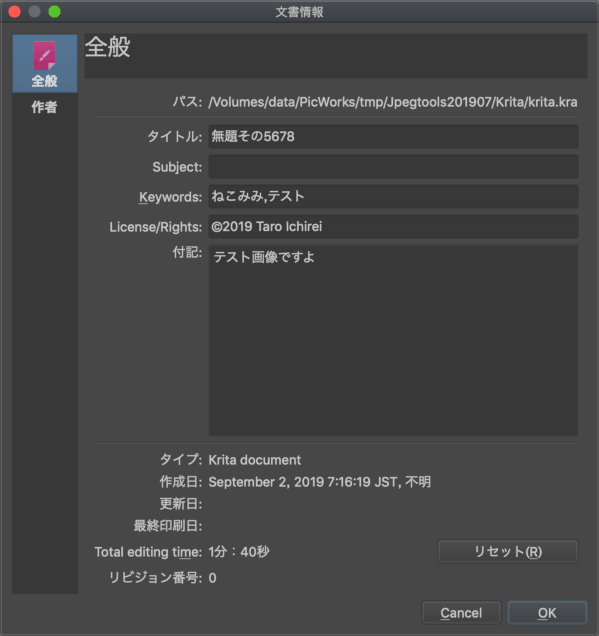 「画像」の情報は、メニューの ファイル > ドキュメントの情報 でダイアログが開きます。ここにも作者の欄がありますが、こちらでは編集はできません。
「画像」の情報は、メニューの ファイル > ドキュメントの情報 でダイアログが開きます。ここにも作者の欄がありますが、こちらでは編集はできません。
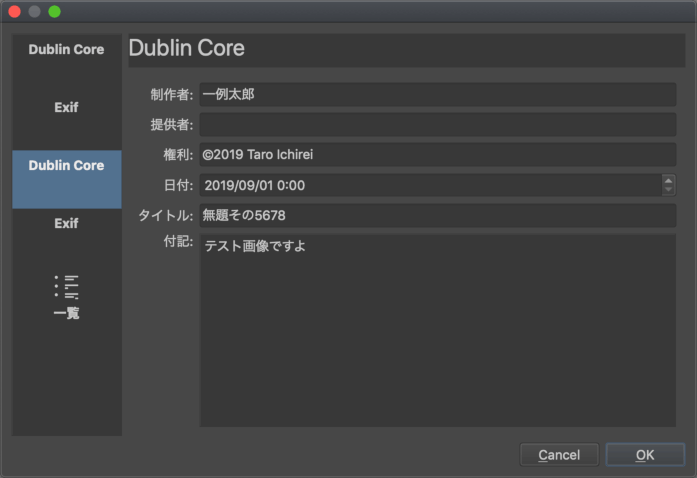 レイヤーが1枚だけならば、レイヤーメニューにある「メタデータを編集...」が使えます(レイヤーが複数ある場合、レイヤーごとにメタデータを設定できますが、JPEGに書き出す際はレイヤーが統合されてメタデータのない新しいレイヤーができる形になるようです)。ここにデータがある場合は、「作者の情報」「画像の情報」よりもこちらが優先されます。
レイヤーが1枚だけならば、レイヤーメニューにある「メタデータを編集...」が使えます(レイヤーが複数ある場合、レイヤーごとにメタデータを設定できますが、JPEGに書き出す際はレイヤーが統合されてメタデータのない新しいレイヤーができる形になるようです)。ここにデータがある場合は、「作者の情報」「画像の情報」よりもこちらが優先されます。
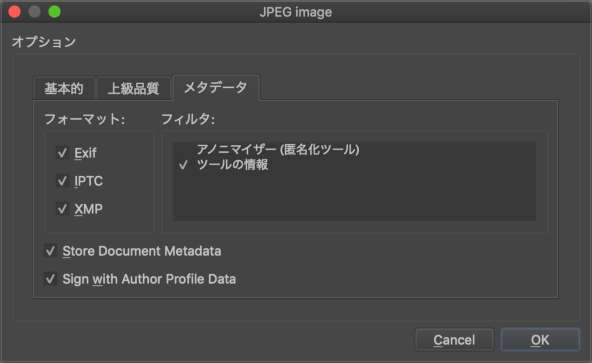 JPEGファイルにメタデータも一緒に保存するには、JPEG保存時のダイアログのメタデータタブ内の「アノニマイザー(匿名化ツール)」のチェックを外し、他はチェックありにします(「ツールの情報」はお好みで)。
JPEGファイルにメタデータも一緒に保存するには、JPEG保存時のダイアログのメタデータタブ内の「アノニマイザー(匿名化ツール)」のチェックを外し、他はチェックありにします(「ツールの情報」はお好みで)。
PaintShop Pro 2020
→PaintShop Pro:Corel 写真編集ソフトウェア
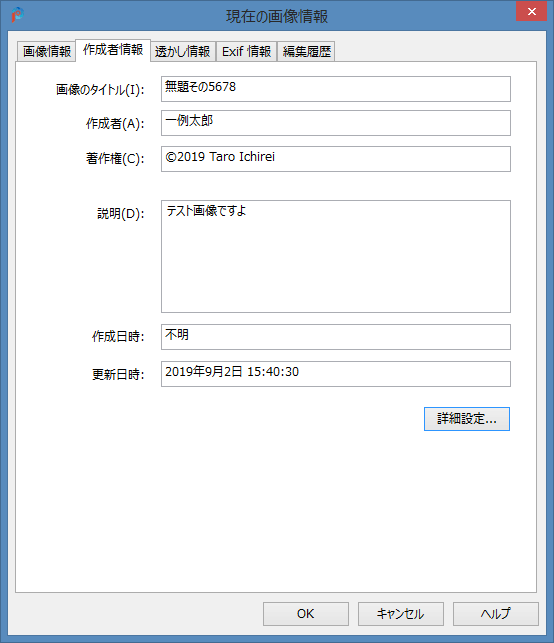 メニューの 画像 > 画像情報(n)... でダイアログが開きます。情報の種類でタブが分かれていて、そのうちの「作成者情報」を開きます。
メニューの 画像 > 画像情報(n)... でダイアログが開きます。情報の種類でタブが分かれていて、そのうちの「作成者情報」を開きます。
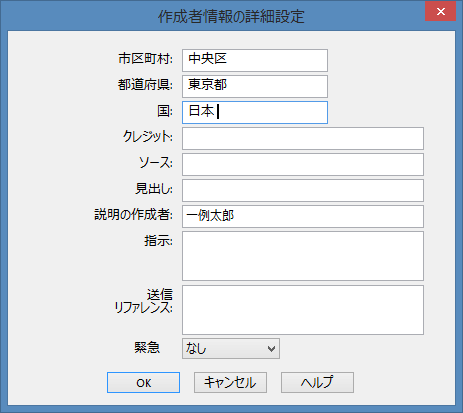 そして右下の「詳細設定...」でもう一つ画面が開きます。
そして右下の「詳細設定...」でもう一つ画面が開きます。
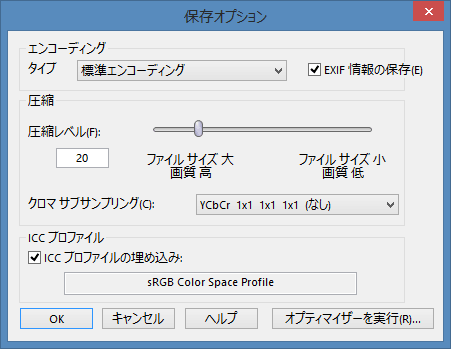 JPEGファイルにメタデータも一緒に保存するには、「名前を付けて保存(A)...」か「コピーに名前を付けて保存(Y)...」を使い、オプション画面を開き「EXIF情報の保存(E)」にチェックを入れます。
JPEGファイルにメタデータも一緒に保存するには、「名前を付けて保存(A)...」か「コピーに名前を付けて保存(Y)...」を使い、オプション画面を開き「EXIF情報の保存(E)」にチェックを入れます。
オプティマイザーやウイザードを使うと、メタデータは保存されません。
ツールによって埋め込めるメタデータの項目に違いがありますが、埋めたい情報を扱えるツールを使っているなら積極的にメタデータを埋め込んでいきましょう。
書き出されたJPEGファイル内のメタデータをもう少し詳しく見てみよう。メタデータはExif、IPTC、XMPの3種類に分けることができる。(XMPはExif、IPTCをはじめ他のメタデータも取り込んでいるので境界はあいまいではある)
※Exifの「ImageDescription」は、Exif規格書では「画像タイトル」と明記されているが、XMP規格書のExifの項目では「画像の説明」とされ、PhotoshopやKritaなどはこれに従っているようだ。それでここでも「画像の説明」とした。
ちなみに各規格書については以下のところで入手できる。
- Exif
- CIPA 一般社団法人カメラ映像機器工業会: CIPA規格類 リストの一番上に「Exif 2.32」と「Exif2.31 metadata for XMP」がある
- IPTC
- IPTC Photo Metadata Standard 2017.1
- XMP
- XMP仕様書(PDF)
では、exiftool(後述)などのメタデータ用ツールで確認してみよう。
Photoshop CC 2019
サンプルJPEG画像: Photoshop「別名で保存」 / Photoshop「書き出し」
○:あり ×:なし —:入力欄がない /:規格にない
通常の保存(「保存」「別名で保存」)では、編集履歴やサムネイルなど多くの不要な情報も記録されてしまうので注意が必要。
「書き出し」では、編集履歴やサムネイルは保存されないものの、キーワードや説明などが保存されない。
GIMP 2.10
サンプルJPEG画像: GIMP
○:あり ×:なし —:入力欄がない /:規格にない
権利の状態はPhotoshopと同じくプルダウンメニューからの3択であるが、なぜか情報が保存されず、ダイアログを閉じた時点で初期値の「Unknown」に戻ってしまう。
GPS情報も編集できるのだが、削除する機能はなく、メタデータを保存すると(JEPG保存時のオプション項目「Save Exif Data」にチェックを入れて保存すると)一緒にGPS情報も記録される。もともとGPS情報を持たない画像の場合は初期値の緯度0・経度0・標高0という嘘情報が記録されることになる。
Krita 4.2
サンプルJPEG画像: Krita(通常) / Krita(レイヤーのメタデータ欄を使用)
○:あり ×:なし —:入力欄がない /:規格にない
※1 後ろにContactInfoの1番最後の項目が追加される
※2 後ろにキーワードが追加される
「作者」と「画像」のメタデータは、入力してもJPEGファイルに保存されない項目が多すぎる(kraファイルには全て保存されるが)。
一方、「レイヤーのメタデータ欄」は、レイヤーごとにメタデータが入力できるが、kraファイルには保存されず、レイヤーが複数ある画像をJPEGで保存するとどのレイヤーのメタデータも保存されない(レイヤーが1枚だけなら保存される)、という謎な仕様。
PaintShop Pro 2020
サンプルJPEG画像: PSP
○:あり ×:なし —:入力欄がない /:規格にない △:文字化け?
メタデータはExifToolではIPTCでのみ保存されているように見える(しかも文字化けしている)が、ほかのPhotoshopなどのツールでは全く認識されない。
メタデータを扱える様々なツールで見てみると、文字化けしている部分がところどころある。そこで疑問が出てくる。「日本語(漢字やかな)を使ってもいいのか?」——
XMPはデフォルトエンコーディングがUTF-8で漢字・かなは問題なし、IPTCはよくわからなかったが、文字コードを明示すれば問題ないようだ。Exifはユーザーコメント以外では直接多バイト文字を使えないが、XMPマニュアルのExifのところを見るとASCII以外はURLエスケープするとあるので、これでExifで漢字やかなを使えるようだ。
また、「メタデータの内容として日本語(漢字やかな)でいいのか」という疑問もある。これは読んでほしい対象をどう考えるかによる。対象が「主として日本語を使う人」ならば当然日本語で書くのがいいことになる。
項目によっては言語別に複数の内容を書けるものもある。XMPの dc:description(作品の説明) 、dc:rights(権利の情報) 、dc:title(作品名) がこれにあたる。ただし、ペイント系グラフィックツールで言語別に書ける機能を持つものはまだ存在しないようだ。
ペイント系ツールでJPEGに書き出すときに完全なメタデータをつけられないなら、後でメタデータを追加する方向で考える。
Exifしか扱えないものではなく、Exif、IPTC、XMP全てを扱えるものを探そう。
→ExifTool by Phil Harvey
この方面ではほぼ最強のツール。例えばdc:descriptionをデフォルト言語(ここでは日本語)・日本語・英語の3通り設定するには次のようにする。
exiftool -xmp:description='テスト画像ですよ' -xmp:description-ja='テスト画像ですよ' -xmp:description-en='This is a test picture.' hoge.jpg
または書き込むメタデータをXMPファイルで用意して次のようにする。
exiftool -tagsFromFile hoge.xmp hoge.jpg
見ての通りコマンドラインツールなので、慣れない人には難易度は高い。なので、GUIでくるんで使いやすくしたツールがいくつかあるのだが、なかなかよいものがない。
ExifToolGUI
→ExifToolGUI
上記のExifToolをGUIでくるんだツール。動作環境はWindowsのみ。表示の日本語が微妙に化ける。
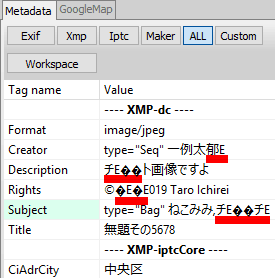
編集/書き込みは日本語でも問題ない。「dc:descriptionをデフォルト言語・日本語・英語の3通り設定する」こともできる(が、書き込む準備が必要。初期状態では書き込める項目が限られているので欄を増やす作業をまずしなければならない)。
XnView MP
→XnViewMP · Image Resizer |Batch Photo Resize | XnView.com
ビュワー機能を中心としたフリーウェア(企業での利用は有料)。動作環境:Win、Mac、Linux。
残念ながらメタデータの編集/書き込みは限られた項目のみだが、表示の方は優秀で、ExifToolでは化けてしまう文字コード指定のないIPTCメタデータもちゃんと表示できる。またExifToolを内蔵していて、ExifToolでのメタデータ表示もできる。
おまけ・ExifToolとCSV
EixfToolはXMPファイルとして用意したメタデータをJPEGファイルに書き込めることは既に述べた。ただ、XMPでは扱えないタグ/プロパティもあるようだ。一方、CSVファイルを使っても同じようにできて、こちらはタグ/プロパティの制限はないようだ。
ということでCSVでのメタデータのサンプルを作ってみた。次のようにしてExifToolで処理する。(参考:exiftoolを使って画像のIPTC情報をcsvでまとめて設定する - Qiita)
exiftool -csv=meta.csv -codedcharacterset=utf8 -charset iptc=latin2 meta-csv.jpg
CSVファイルはテキストエディタでも編集できるが、やはり表計算ソフトを使うのが確実だろう。表計算ソフトで開くと、上の行にタグ名が並び、下の行には対応する中身が並ぶ形のデータになっている。また、CSVファイルの中に処理するJPEGファイル名を明記しておかないといけない点に注意。
メタデータ用CSV / サンプルJPEG画像(ExifTool+CSV)
Catalinaにしたよ。事前に情報収集してなかったので、アクセス制限の厳しさにびっくりしているところ。許可がないアプリはデスクトップや外付けHDDのファイルにアクセスできない。普通はその場で確認のダイアログが出るのでOKすれば、アプリが許可リストに登録されて問題ないのだが、GIMPなんかは許可リストに登録しても拒否られる。多分普通のアプリとはファイルアクセスの仕組みが違うのだろう。制限のかからないフォルダでは問題ないので当分はそこで作業をすることでしのぐ事になるだろうな。
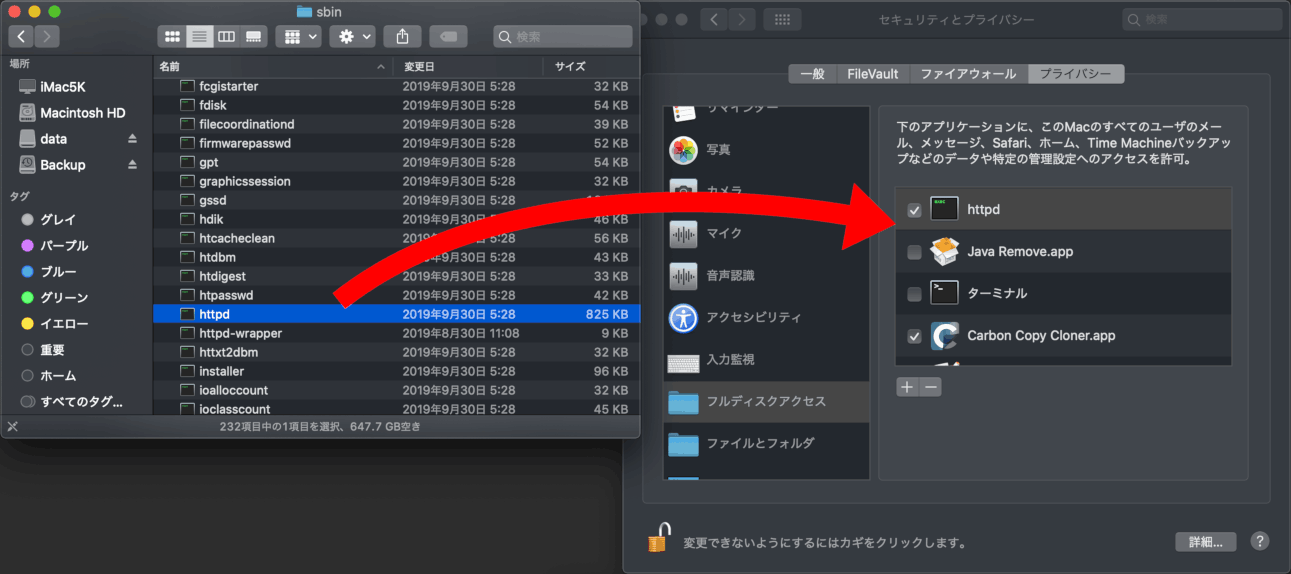
続いてApache。バージョンアップの際には必ず設定ファイルの変更があるのだが、今回は前の設定ファイルが「場所が変更された項目」というフォルダに隔離されている(デスクトップにエイリアスができるのですぐにわかる)。diffコマンドで違いを表示させて設定を書き換えてApacheを再起動。そうしたら「403 Forbidden」でローカルサイトが表示されない。サイトのファイルのありかが外付けHDDなので、アクセス制限に引っかかってたわけね。これはApacheの実体、/usr/sbin/httpd を許可リストに登録する事できれいに解決できた(Finder の「移動 > フォルダへ移動...」で /usr/sbin を開き、httpdをリストの中へドラッグ&ドロップ)。
そしてフォント。「ダウンロードできるフォント」の位置が変わっている。/System/Library/Assets/.. から /System/Library/AssetsV2/.. へ変わった。それで前に書いたスクリプトが対応できなくなったので修正版を書いた。 Catalina対応版ダウンロード 使い方は前と同じ。
Catalinaにアップグレードしてから一部のサードパーティ製アプリの文字の表示がちと変になった。以前と違うフォントで表示されている。
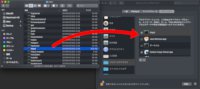
 これはFireAlpaca最新版2.1.21の環境設定ダイアログ。比較のため旧OS版を並べた。手元に前バージョンMojaveがないのでその前のHigh Sierraを使ったが、Mojaveと変わらない...と思う。
これはFireAlpaca最新版2.1.21の環境設定ダイアログ。比較のため旧OS版を並べた。手元に前バージョンMojaveがないのでその前のHigh Sierraを使ったが、Mojaveと変わらない...と思う。
Catalinaではヒラギノ角ゴProがなくなったようなので、その影響かも。見たところ中国語フォントが使われているっぽい(拗音・発音の小さいかなの字(「ッ」や「ィ」など)が上下方向の中心に来ていることから)。元々使っていたフォントが見つからずに別のフォントが使われているんだろうけど、なぜ中国語フォントなんだろう。
 ねこみみさん。FireAlpaca使用。
ねこみみさん。FireAlpaca使用。
2019年末にあったInkscapeの「About Screen Contest for 1.0」に参加しました。ヘルプメニューの「Inkscapeについて(Aboout Inkscape)」で表示される画面用のイラストを募集するコンテストです。(参加作品ギャラリー、募集要項[一番下に歴代の作品があります])
 クリックするとSVG版が表示されますが、スクリーンモードなどを使っているので、ブラウザではちゃんと表示できないと思います。
クリックするとSVG版が表示されますが、スクリーンモードなどを使っているので、ブラウザではちゃんと表示できないと思います。
Inkscape1.0Betaも使って描きました。こんな作品にも投票してくれる人がいて、ありがたい限りです。
 おまけ。こっちは全部GIMPで描いてみた。
おまけ。こっちは全部GIMPで描いてみた。


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}